Target rate for class imbalance
Class imbalance is a common problem in machine learning, where the negative class greatly outnumbers the positive class (or vice versa). I recently watch a talk from stripe where they share their techniques in addressing class imbalance in a credit card fraud detection system. I decided to create a summary here and try it out for myself on a credit card fraud public dataset.
Target rate
The objective is to create a model which can predict whether a transaction is fraudulent. The model is a binary classifier which produces a score in the 0-1 range, where 0 indicates no fraud and 1 indicates fraud. Based on what they’ve found, training on imbalance data and validating the metrics on imbalance data produces worse result compared to training and validating on a more balanced data. Why?
With a binary classifier model, we need to choose a threshold that satisfies some criteria on the validation data. This threshold is used to determine whether an instance is going to predicted as fraud or not. What they want to do in their case is that they want to maximize recall while capping FPR (false positive rate). Say we have initially a training + validation data with less than 1% fraudulent label (the positive label). If we optimize only for recall and FPR, we can get a low FPR but extremely low precision. Why is this happening? FPR is low because the denominator of the negative label is extremely huge. The model can predict a lot of false positives and still get low FPR in this case. Then during the threshold picking phase on the validation set, we can just pick a relatively low threshold, which results in high recall but extremely low precision. Hence we need to do something on the class imbalance.
However, if we train and validate on a balanced dataset, we are going to be faced with class imbalance again on the production. That is why we need to find a balance that works best in production.
Their idea is to try to create a balanced training set that works well on the extremely imbalanced production data. Basically what we want to find is a percentage of fraud (x%) and the percentage of non-fraud training data instances (100-x%) that maximizes performances on the validation data which still contains the original proportion of the class imbalance. The percentage (x) is called the target rate. Then what we do is we can use grid/exhaustive search, trying out different values of x by keeping every fraudulent dataset and downsample the non-fraudulent dataset to create the dataset according to the target rate. After that, they evaluate the performance in validation set and also the performance in production.
My own experiment
To see how helpful is this target rate idea, I decided to try it out on a credit card fraud public dataset. The dataset is extremely imbalanced with only 0.0001 percent of fraud dataset. I try different target rate from 0.1 to 1 and train XGBoost model with the balanced training data. Then I evaluate the XGBoost model on the imbalanced validation set and below is the result I get:
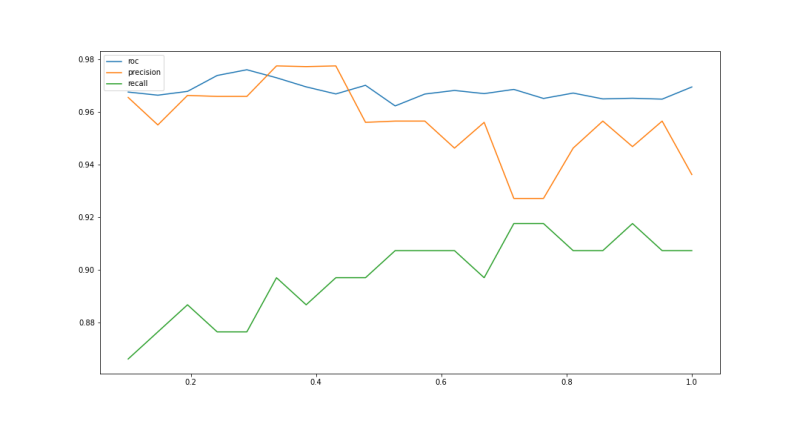
We can see that the graph looks wiggly, and perhaps that the best tradeoff between the three metrics is between 0.3-0.4 target rate. Now I would say that this technique is helpful to some extent if we want to do better downsampling. However, I think that the result is prone to random samples and the random seed that we initialize. So I’m not entirely convinced that this is the best method to overcome extremely imbalanced dataset.
Closing
Thanks for reading! If you think I am missing something please comment below. For those interested you can check my code here.